
Retrieval-augmented generation is what people mean when they say "AI that answers from your own documents." The pattern pairs a language model with a search system over your data, so the model answers from passages it has just been handed rather than from whatever it absorbed during training. It is the most reliable way to ground an LLM on private, current or domain-specific content without touching the model's weights.
The term comes from a 2020 paper by Lewis et al., so the idea is not new. What has changed is that the surrounding tooling, vector databases, embedding models, rerankers, has matured enough to make production deployments practical for most teams.
What RAG actually does
A pure LLM answers from its parameters. Ask it about your internal returns policy and it will either refuse, guess, or produce something plausible-sounding and wrong. RAG inserts a retrieval step before generation: the user asks a question, the system searches a knowledge base for the most relevant passages, stuffs them into the prompt, then asks the LLM to answer using that context.
Three useful properties follow from this design. The model can cite the passages it used, so answers are auditable. The knowledge base can be updated independently of the model, so freshness is a deployment problem, not a retraining problem. Your documents never enter model weights, which matters for governance.
The price is complexity. You now run a search pipeline, a vector database, an embedding model and a generation model, plus the glue and monitoring that hold them together.
The pipeline from document to answer
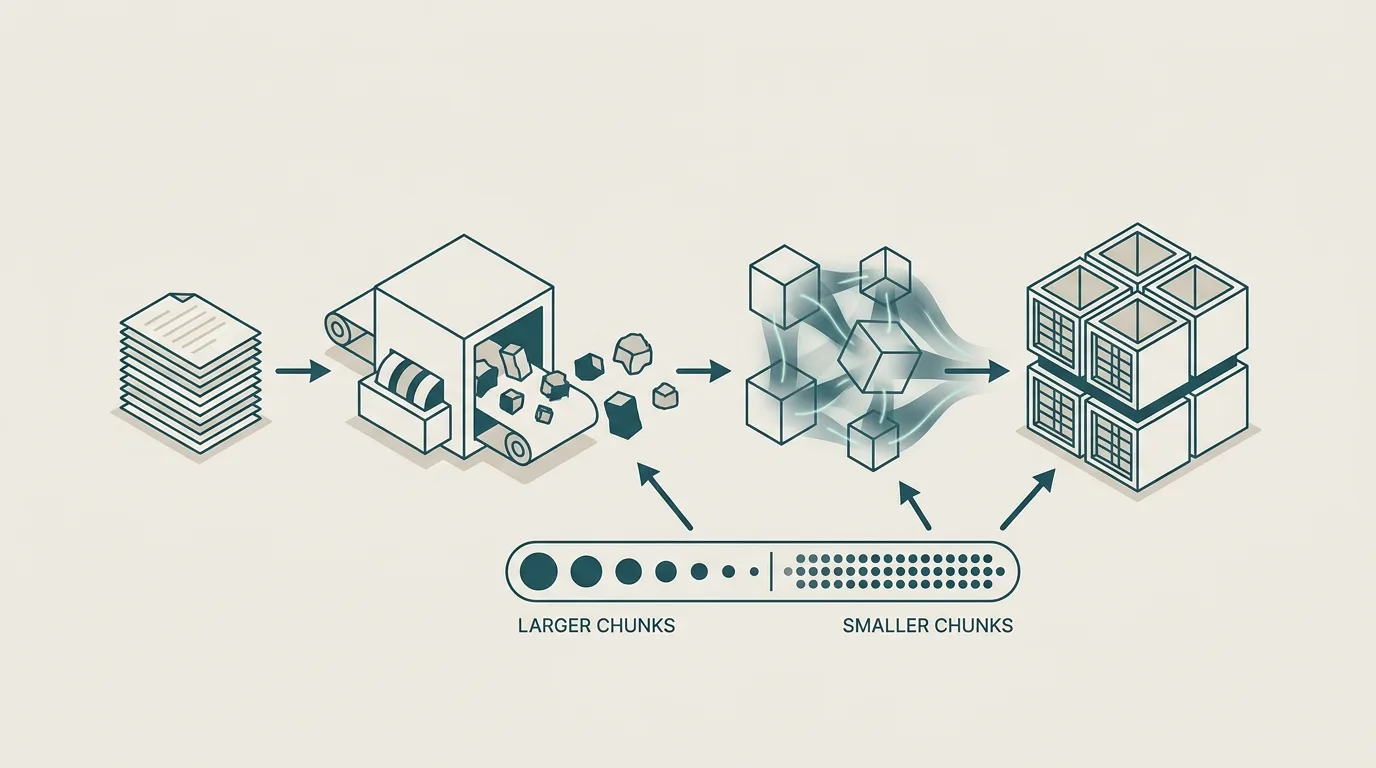
A production RAG system runs two pipelines, not one. An offline pipeline ingests, chunks, embeds and indexes documents. An online pipeline retrieves, reranks and generates at query time. Treating these as separate concerns is the first design decision worth making.
Indexing and chunking
Indexing converts your source corpus, PDFs, Confluence pages, support articles, contracts, into vectors and stores them. The chunking step inside it is the one most articles skip, and it is the one that quietly decides how well the whole system works.
Chunks that are too large dilute the embedding's meaning and waste prompt tokens. Chunks that are too small lose context and force the retriever to stitch together fragments. A workable starting point for batch ingestion is 500 to 1,000 token segments with some overlap, but the right strategy depends on what you are indexing.
For structured documents with headings and sections, hierarchical chunking, where you keep the section path attached to each chunk, tends to do far better than flat splits. For long narrative content, semantic chunking that splits on topic boundaries works best. For short, self-contained articles like support FAQs, fixed-size chunking is fine. There is no universal answer, which is why "we set chunk_size=512 and called it done" is the most common cause of mediocre retrieval.
# Example: hierarchical chunking preserves the section pathchunk = { "text": "Refunds are issued within 14 days...", "metadata": { "doc": "returns-policy.pdf", "section_path": ["Returns", "Refunds", "Timing"], "page": 3, },}Retrieval and reranking
At query time, you embed the user's question with the same model used for indexing and find the nearest chunks in the vector store. This is the dense retrieval step. The naïve version stops here, and the naïve version is why so many RAG demos look great until someone asks a question that hinges on a specific product code or proper noun.
A reranker is a second, slower model that scores each candidate against the query directly, rather than via embedding similarity. Pulling 50 candidates with hybrid search and then reranking down to the top 5 is a common production pattern, and it is usually the single biggest accuracy win once your chunking is sensible.
Augmentation and generation
Augmentation is the boring step that matters more than people expect. You take the reranked passages and assemble a prompt that tells the model: answer the question using only the context below, cite the source for each claim, and say "I don't know" if the context does not contain the answer. How you phrase that system prompt directly shapes hallucination rates.
Generation is then handed to whatever LLM fits your constraints: GPT-4, Claude Sonnet, Llama 3 or Mixtral. The model is doing less clever work than you might think. It is reading the passages you gave it and writing them up.
Why retrieval quality is where most systems fail
When a RAG answer is wrong, the failure is almost always upstream of the LLM. The model was handed the wrong context, or insufficient context, and did its best with it. Investing in the generator before fixing retrieval is the most common wasted month in this space.
Hybrid search: dense plus sparse
Dense retrieval captures semantic meaning. It will match "how do I get my money back" to a passage about refunds even though the words do not overlap. What it handles poorly is exact tokens: product SKUs, error codes, surnames, acronyms.
Sparse retrieval, BM25 keyword matching, does the opposite. Hybrid search runs both and merges the results. Practitioner reports vary on the exact magnitude, with some posts claiming around a 17 percent recall improvement over dense-only and others putting the range at 1 to 9 percent, but the direction is consistent: hybrid beats either approach alone, and it is the default for serious production systems.
A practical default
If you are starting a new RAG project today, turn hybrid search on from day one. Qdrant, Weaviate and Pinecone all support it. The added complexity is small. The quality difference on real, messy queries is not.
Chunking strategy by document type
Match the chunker to the content, not the other way round. A contracts corpus with clauses and sub-clauses wants hierarchical chunking that preserves clause numbering. A wiki of long-form articles wants semantic chunking on topic boundaries. A help centre full of short, single-purpose articles can usually keep entire articles as single chunks. The mistake is picking one chunker and applying it to every source.
RAG vs fine-tuning: how to choose
This is the question we get most often when scoping AI development services, and the answer is usually "RAG first, fine-tune later, and only if you have to."
RAG is the right default when the goal is to answer from a body of knowledge, when that knowledge changes over time, when you need citations, or when the data is sensitive. Fine-tuning is the right tool when the goal is to change how the model writes or reasons, not what it knows: a specific tone of voice, a domain vocabulary, a structured output format the base model keeps getting wrong.
The trade-offs that usually decide it:
- Freshness. Updating a RAG index is a re-ingest. Updating a fine-tuned model is a retraining run.
- Cost. Building a vector database is far less resource-intensive than repeated fine-tuning cycles, as Red Hat and others have noted.
- Auditability. RAG can cite its sources. Fine-tuned answers cannot.
- Style. RAG cannot easily teach the model to write like your brand. Fine-tuning can.
When to combine them with RAFT
The two techniques are not mutually exclusive. Retrieval-Augmented Fine-Tuning (RAFT) is the hybrid: fine-tune a base model on your domain so it understands the terminology and reasoning patterns, then put it inside a RAG system so it can pull current facts at query time. A financial analyst assistant is the canonical example. Fine-tune on a corpus of analyst reports to learn the language, then retrieve live market data through RAG to ground specific answers.
For most teams reading this, RAFT is a step two. Get RAG working well first. If your only remaining problem is that the model sounds wrong rather than that it is wrong, then look at fine-tuning the generator.
Get plain-English guides like this in your inbox.
One short email a month. WordPress, Shopify, SEO, no fluff. Unsubscribe in one click.
We never share your email.
Data governance and the self-hosted option
Teams that decide RAG is a non-starter usually fall into two camps. Some have use cases that genuinely do not need external knowledge, creative writing or code generation from scratch, and a vanilla LLM serves them fine. The rest are blocked by data governance: they cannot send documents to a third-party embedding API.
Self-hosting solves the second problem. Open-source embedding models like BGE and GTE-Qwen2 are competitive with commercial offerings and can run inside your own infrastructure. Pair them with a self-hosted Qdrant or Weaviate instance and an open-weight generator like Llama 3 or Mixtral, and your documents never leave your network. You pay in operations effort what you save in legal risk.
This is one of the genuine advantages of RAG over fine-tuning a hosted model. Your sensitive data sits in a private knowledge base, accessed at query time, and is never baked into a third party's weights.
The question is not "can AI answer from our documents". The question is whether your documents are organised well enough that a search system can find the right ones. That problem predates AI.
The reference stack for production RAG
There is no single right stack, but there is a sensible default that most production systems converge on:
- Parsing: Apache Tika or Unstructured.io for PDFs, DOCX and HTML.
- Chunking: semantic or hierarchical splitters from LangChain or LlamaIndex.
- Embeddings: BGE or GTE-Qwen2 self-hosted for sensitive data, OpenAI's text-embedding-3-small for convenience.
- Vector database: Qdrant self-hosted, or Pinecone managed, with hybrid search enabled.
- Reranker: a cross-encoder model called on the top 20 to 50 candidates.
- Generator: GPT-4, Claude Sonnet, Llama 3 or Mixtral depending on privacy and quality needs.
- Observability: retrieval metrics (recall, MRR), answer fidelity checks, and latency targets such as time-to-first-token under two seconds at the 90th percentile.
The choice between managed and self-hosted at each layer is the same decision you make everywhere else in software, and we have written about that trade-off in build vs buy: when custom software beats off-the-shelf. RAG is no different.
Failure modes worth knowing before you build
A weekend prototype hides the failure modes a production system will eventually hit. Worth knowing in advance:
- Stale indexes. A document changes upstream, the index does not, and the model confidently cites the old version. You need idempotent ingestion and a re-index trigger tied to source changes.
- Embedding model drift. When you upgrade the embedding model, every existing vector is now in a different space. You have to re-embed the entire corpus. Budget for this when you choose a model.
- Multi-tenant leakage. If your system serves multiple customers, namespace isolation in the vector store is not optional. Test it before you ship.
- Citation hallucination. Models will sometimes cite passages they did not actually use, or invent a citation that looks like the real format. Validate citations programmatically against the retrieved set.
- The "I don't know" problem. Models trained to be helpful resist refusing. You will need explicit prompt instructions and, often, a calibration step where you reject low-confidence answers.
If you are adding a RAG feature to an existing product, the broader principles in adding AI features to your product without the hype apply. Scope tightly, measure honestly, and ship the boring version first. If your goal is to be the answer that other AI systems cite back to users, that is a different problem with its own playbook in generative engine optimisation: how to get cited by AI Overviews and ChatGPT.
RAG is not magic. It is a search problem with a language model attached to the end. Teams that treat it that way ship working systems. Teams that treat it as an LLM problem spend months tuning prompts to compensate for retrieval they never fixed. If you want a sense of what we build with these patterns, see what we've built.